Recommending similar apparel items/products in ecommerce based on Text and Image Features.
Business objective
Recommending similar apparel items to user. Its estimated that amazon’s 35% revenue is generated using product recommendations.
Approach
We have two approaches here,
-
Content based recommendation: As its name suggests, we do content based recommendation, means its based on tittle text,Description text, images.
-
Collobarative filtering based recommendation: This recommendations are done based on the behaviour of the user.A small example can be seen,
if U1 ===> I1,I2 ,I3 (Purchases or Searches) # U-User , I-Item
and U2 ===> I1,I3,I4
then U3 ===> I1,(I3) # recommend user 3 item I3 as he purchased I1.
U3’s recommendations came from behaviour of similar users as he purchased I1. This is Collobarative filtering. But, Amazon doesnt provide users data, so we are not going to do collobarative filtering. Instead we use content based.
Plan of Attack
These are the steps we follow during this project.
- Data aquisition
- Data Cleaning
- Text Processing (NLP)
We solve this problem with both Text based and Image based.
- Text based product recommendation
- Bag of Words
- Term frequency-Inverse document frequency (TF-IDF)
- Word2Vec
- Avg W2V
- TF-IDF weighted W2V
- Image based product recommendation
- Using CNN deep learning techniques
1. Data Aquisition:
We can use Amazon’s Product Advertising API, and get the required data. We took womens tops as the dataset . It consists of 183000 datapoints, having 19 features each.
Index(['asin', 'author', 'availability', 'availability_type', 'brand', 'color',
'editorial_reivew', 'editorial_review', 'formatted_price',
'large_image_url', 'manufacturer', 'medium_image_url', 'model',
'product_type_name', 'publisher', 'reviews', 'sku', 'small_image_url',
'title'],
dtype='object')
But we use only 6 features for this project.
- asin ( Amazon standard identification number)
- brand ( brand to which the product belongs to )
- color ( Color information of apparel, it can contain many colors as a value ex: red and black stripes )
- product_type_name (type of the apperal, ex: SHIRT/TSHIRT )
- medium_image_url ( url of the image )
- title (title of the product.)
- formatted_price (price of the product)

2. Data Cleaning
Basic Stats of every feature
For every feature we ask these questions
- How many missing values are present.
- Whats top frequent item, and how many times its repeating.
- We also see, top 10 most repeating words.
As part of processing times and power, I just removed all the points that have missing datapoints in any feature. Just removed all the datapoints that have null value in feature columns formatted_price and color. after this we left with around 28000 datapoints. If you see, we have a feature named medium_image_url this is url for our apparel image of medium size. Uisng Python Imaging Library (PIL) got all those images and saved them.
Remove near duplicate items
If we observe the feature title, there are many similar duplicate texts only varying in colors or sizes in its title like,
25. tokidoki The Queen of Diamonds Women's Shirt X-Large
26. tokidoki The Queen of Diamonds Women's Shirt Small
27. tokidoki The Queen of Diamonds Women's Shirt Large
61. psychedelic colorful Howling Galaxy Wolf T-shirt/Colorful Rainbow Animal Print Head Shirt for woman Neon Wolf t-shirt
62. psychedelic colorful Howling Galaxy Wolf T-shirt/Colorful Rainbow Animal Print Head Shirt for woman Neon Wolf t-shirt
63. psychedelic colorful Howling Galaxy Wolf T-shirt/Colorful Rainbow Animal Print Head Shirt for woman Neon Wolf t-shirt
64. psychedelic colorful Howling Galaxy Wolf T-shirt/Colorful Rainbow Animal Print Head Shirt for woman Neon Wolf t-shirt
We remove these datapoints and also remove those datapoints which have words less than 4 in the title. We are left with 16000 datapoints.
Text Preprocessing
We remove stop words and do stemming.
4. Text Based Product Recommendation
We convert text to vectors using 1. Bag of words
2. TF-IDF
3. Word2Vec
We find the euclidean distance between the query text and the data set , return the datapoints which has lowest distance. smaller the distance greater the similarity.
5. Image based Product Recommendation
Using Transfer learning, we use VGG 16 algorithm to convert images data into vectors. We return the products with smallest distance.
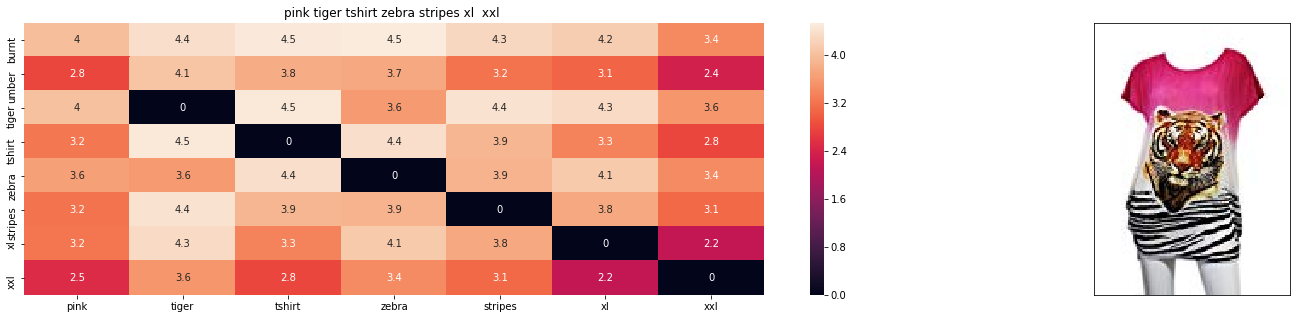
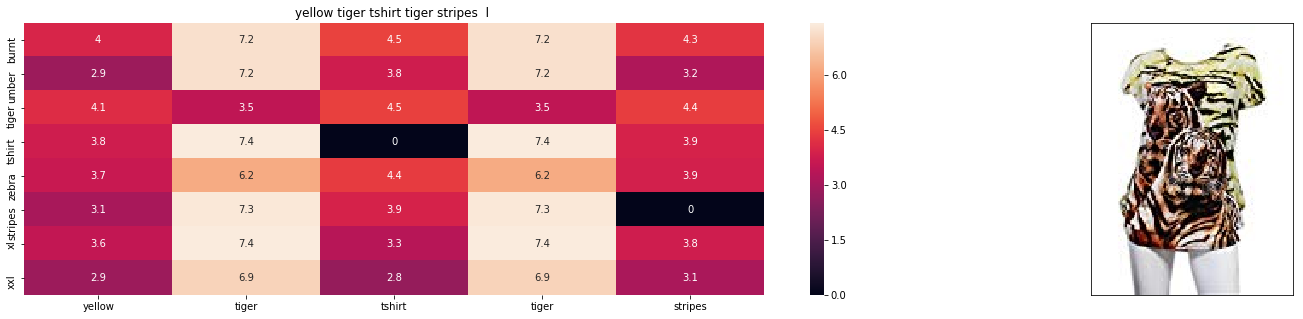
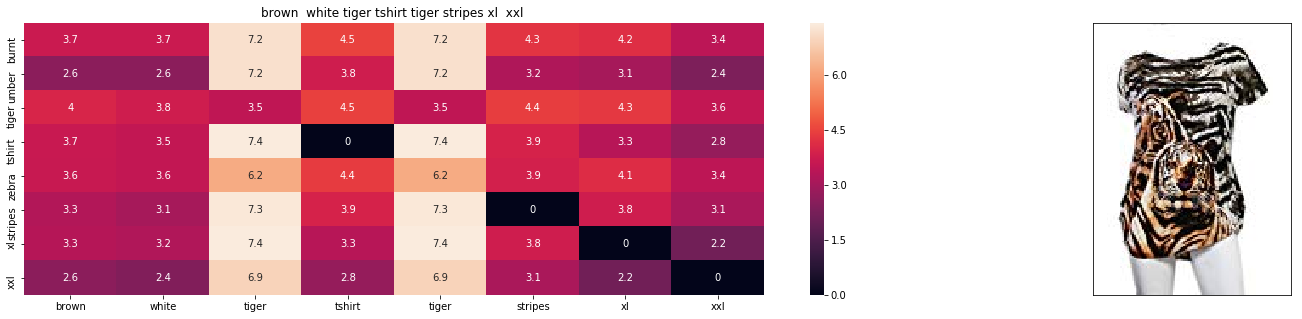
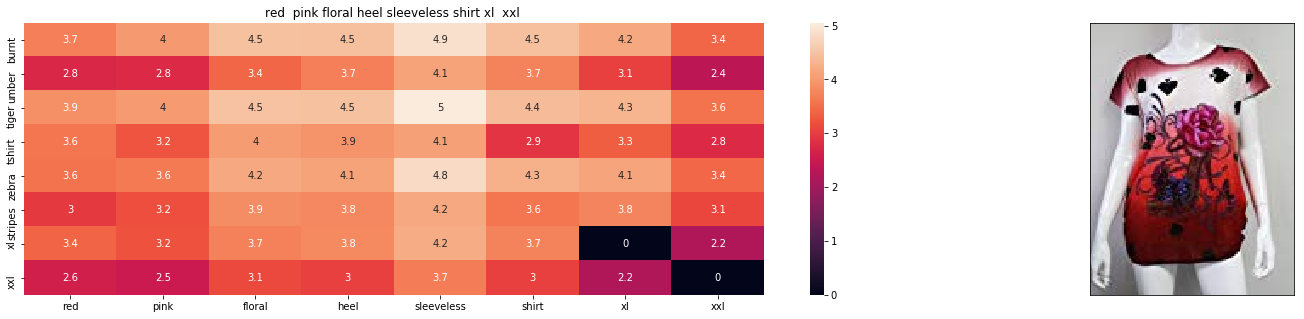
6. Results
Finally we combine text and image features and see the recommendations
Query Image

Recommended Apparels